
Are you getting ready for a system design interview?
Below, we summarize the most common system design interview questions, principles, and interview prep tips.
Read more: Recent interview experiences from engineers.
System Design Interview
A system design interview is a 45- to 60-minute conversation where you architect a software system from scratch.
The interviewer gives you a prompt ("Design Instagram," "Design a rate limiter," "Design a batch inference API for a GPU cluster"), and you spend time deciding which components the system needs, how data flows through it, and what trade-offs you're making.
There's no single correct answer. The interviewer is evaluating how you think, not checking your diagram against a key.
This guide covers what's changed in 2026, what interviewers at specific companies look for, the exact questions candidates have been asked, and how to structure your preparation.
System Design in 2026
The bar is higher
An Airbnb engineering interviewer with over a decade of experience building distributed systems described what he's seeing from the inside:
"Even candidates with stellar reviews are getting declined at the end for an offer. The same high scores are getting fewer offers, even though they used to get the offers."
This isn't unique to Airbnb. Across major tech companies and AI startups, the number of strong candidates passing technical bars exceeds open headcount.
AI and LLM infrastructure design
A year ago, "design a system that serves an LLM" was reserved for ML engineer roles.
Now it's showing up in general software engineer loops.
Real system design interview questions from 2026 include:
- Design a high-level system for a large language model responding to a user query.
- Design a customer-support chatbot integration on top of a third-party LLM platform.
- Distribute one huge file (like model weights) to thousands of machines over a constrained network link.
- Prioritize and allocate distributed compute resources across multiple projects.
- Design safeguards for an AI system that can take actions on behalf of a user.
At Robinhood, a software engineer reported being asked to design a highly distributed training system.
At Anthropic, an infrastructure SWE described their loop as "a coding round, a system-design round, a hiring-manager round, a culture round, and a technical-project deep dive, very tied to GPU infrastructure and Anthropic's safety culture."
If you're interviewing at any company that ships AI features, expect at least one prompt involving LLM serving, embedding pipelines, or GPU resource management.
The underlying infrastructure patterns (queuing, batching, load balancing, async processing) are the same distributed systems patterns you already know.
New interview formats
The classic format (one open-ended whiteboard problem) is still the default at most companies. But newer formats are showing up.
The focus of newer interviews is around high-level conversations. The bar higher than ever for serious candidates. And interviewers want to hear you think in real-time, not just whiteboard a solution.
At Stripe and some AI labs, instead of one open-ended problem, candidates receive a single problem broken into three to five sequential parts on a HackerRank-style platform.
Each part unlocks only after the prior part's code runs cleanly.
A Stripe SWE said, "the question is given in several parts and each part's completion is required to proceed to the next, with three parts total under 45 minutes. Another candidate encountered the same pattern on CodeSignal in an in-memory database round.
Practice incremental builds where you ship a working v1 fast, then layer features. Don't over-design v1. The grader needs it to pass before you see v2.
At Amazon, particularly for GenAI Architect roles, the phone screen system design round may have no whiteboard at all.
One senior candidate said, "The interviewer said we'll be talking casually. But then, they asked me to design the system verbally without a diagram. Then, he pressed me to upgrade the functional and non-functional requirements on the spot."
Many candidates in our research completed their rounds without any shared diagramming tool.
Some candidates drew on paper to organize their own thinking. Others didn't diagram at all.
Cost and operational reasoning
A few years ago, hand-waving about "we would add more servers" was acceptable when discussing scale. In 2026, interviewers at multiple companies explicitly evaluate whether you can reason about cost, monitoring, failure modes, and operational maturity.
Discussing cost trade-offs (when to use spot instances, when to cache versus recompute, when serverless makes sense) separates you from candidates who memorize architectures.
System Design Interview Questions
View more recently asked system design interview questions:
AI and LLM infrastructure
- Design a system for an LLM responding to user queries (Google)
- Design the OpenAI Playground (OpenAI)
- Design a customer-support chatbot on a third-party LLM (rate limits, fallback, state)
- Design a batch inference API for a GPU cluster (Anthropic)
- Design an agentic AI system that can autonomously adapt to new tasks (Anthropic)
- Distribute model weights to thousands of machines over a constrained link
- Prioritize and allocate distributed compute resources across projects
- Design safeguards for an AI system that takes actions on behalf of a user
- Design a highly distributed training system (Robinhood)
Classic distributed systems
- Design an over-the-air software update system for millions of devices (Microsoft)
- Design a process dependency and failure detection system (Bloomberg)
- Design a URL shortener (like Bitly)
- Design a key-value store
- Design a rate limiter
- Design a distributed message queue
- Design a web crawler
- Design typeahead/autocomplete for search
Social and real-time systems
- Design Instagram
- Design Twitter/X
- Design Facebook Messenger or WhatsApp
- Design TikTok
- Design a notification system
Media and content delivery
- Design YouTube
- Design Netflix
- Design a dynamic recommendation system for Netflix
- Design Spotify
- Design Dropbox or Google Drive
Data processing and pipelines
- Design an event processing and data ingestion pipeline (Airbnb)
- Design a web crawler
- Design a metrics and logging service
Commerce and transactions
- Design Ticketmaster
- Design a hotel booking service
- Design a ride-sharing service (like Uber)
- Design a payment system
- Design an e-commerce product page at scale
API and low-level design
- Design a cache with LRU eviction
- Design a collaborative text editor (operational transforms vs. CRDTs)
- Design an in-memory database
System Design by Company
Every company claims their system design round is unique. Some actually are.
Research the service your team works on and the services it interacts with. This is especially true for team-dependent interviews (Netflix, Apple, Amazon).
Google system design rounds are 45 minutes with a single interviewer. Questions tend to avoid Google's actual products, so you're unlikely to design Google Search or Gmail. Expect general distributed systems problems or product-adjacent designs.
Google places particular weight on database selection.
A Google EM who recently went through the loop recommended studying Google's internal database products (Bigtable, Spanner, Firestore, BigQuery) and approaching problems with their internal tech rather than defaulting to AWS or Azure.
Understanding why you'd pick a specific database for a specific workload matters more than knowing Google's internal product names.
Google system design interview guide →
Meta
Meta's system design round is 45 minutes for ICs. For IC roles (E4 and above), the round focuses on distributed systems architecture: designing products Meta actually builds, like social feeds, messaging platforms, or content delivery networks.
Common prompts include "Design Instagram" or "Design a file storage system."
Meta calls the round "Pirate" internally, and some candidates now go through a "Pirate X" loop focused on API and product design.
For engineering managers, the question is filtered through a domain lens. If you're joining a security-focused team, you'll design the security architecture for a system using the STRIDE framework rather than the system itself.
A Meta EM we spoke with described the on-site as including a "learning systems design interview" alongside a project deep dive, team management round, and behavioral round.
Scale is always front of mind. The interviewer expects you to proactively address how your architecture handles billions of users across Facebook, Instagram, WhatsApp, and Messenger. If you don't bring up scale yourself, your interviewer will ask about it, and reactive answers score lower than proactive ones.
Meta system design interview guide →
Amazon
Amazon's system design interview is unusual because behavioral questions are woven directly into the technical round.
An Amazon SWE confirmed, "In the system design interview, there's also a section where the interviewer is going to ask you some behavioral questions."
Expect to design Amazon-type products (Alexa, Prime Video, a logistics system) and connect your design decisions to Amazon's Leadership Principles.
The phone screen system design round may be entirely verbal with no whiteboard or diagram tool for GenAI roles.
Practice articulating design decisions out loud without any visual aid.
Amazon system design interview guide →
Apple
Apple's format, duration, and domain focus vary more widely than at Google, Meta, or Amazon. The round is 45 to 60 minutes; ICT5 candidates on some teams go through two separate system design rounds.
Questions are likely to be domain-driven and reflect the team's actual product area. Privacy, authentication, API design, and storage trade-offs come up consistently. On mobile-focused teams, Apple takes mobile system design more seriously than most companies.
Be prepared to reason about on-device computation, offline behavior, and resource constraints.
Apple system design interview guide →
Netflix
Netflix's system design round is 60 minutes and appears once for L4 candidates, twice for L5 and above.
You might not draw a diagram. Candidates in our research completed their rounds without any shared diagramming tool.
The rounds aren't structured around a standard framework. They're open-ended discussions.
One candidate answered, "After you open the Netflix app and select a viewing profile, Netflix displays a collection of recommended titles organized into categories. How would you design a dynamic recommendation system?"
Another candidate, interviewing for an internal tooling team, got a question about a real architectural decision the team was facing.
A Netflix SWE we spoke with said the system design round was his favorite part of the final loop. The format rewards engineers who can reason about real problems in conversation.
Study the Netflix Tech Blog thoroughly. Candidates who did said it was their most valuable prep resource.
Netflix system design interview guide →
Airbnb
Airbnb's on-site loop has four technical rounds: coding, code review, system design, and architecture review (a reverse system design round where you present a past project).
The code review round is rare in the industry and a strong leveling signal.
For system design, Airbnb draws from a global question bank. Questions are kept intentionally vague. The candidate determines scale, device count, data frequency.
A representative example: design an event processing system that ingests smart meter data and enriches it with an external geolocation service. "I really want to see how candidates think about systems and failure modes," an Airbnb interviewer told us.
The architecture review asks you to present a project you've led. Some candidates bring slide decks with before-and-after diagrams. Others draw on a whiteboard.
The signal the interviewer is looking for is, "can you describe not just what you did, but why, and what decision points led you there?"
At the staff level, the interviewer expects you to connect dots across teams and think beyond the boundaries of your immediate project.
The hiring manager screen is the biggest bottleneck at Airbnb. Once you pass it, conversion rates are high. But managers are looking for very specific experience that maps to their team's needs.
OpenAI
OpenAI expects you to think across the entire stack, from front-end wireframes to API design to database choices, with scalability as the central concern.
Scale is the single most consistent evaluation criterion. Interviewers routinely push designs to 10x, 100x, and 1000x the initial requirements to test how your architecture evolves under pressure.
OpenAI determines your level (senior or staff) after the interview, not before. All candidates go through the same rounds regardless of target level. The system design rounds carry significant weight in leveling decisions.
OpenAI system design interview guide →
Anthropic
Anthropic's system design questions are framed around AI workloads, but the core problems are classic distributed systems challenges.
The most commonly reported question is designing a batch inference API for a GPU cluster. The patterns it tests (queuing, batching under constraints, async-to-sync mapping, GPU resource management) are general infrastructure patterns.
Anthropic interviewers explicitly look for candidates who abstract the AI framing. "Batch inference on a GPU" becomes "batched processing on a constrained compute resource."
The bar is exceptionally high. Candidates who perform well on every technical round still get rejected. Questions lean toward novel problems where even the interviewer may not know the optimal solution.
Anthropic system design interview guide →
Stripe and multi-part builds
Stripe has moved toward a multi-part sequential format on HackerRank where each part unlocks only after the prior one passes.
AI-first startups
At Robinhood, candidates reported being asked to design a highly distributed training system.
At LangChain, some system design rounds were in a reverse format. "Talk about your past systems" and defend your design decisions.
At xAI, a candidate described the technical interview as functionally equivalent to an on-site system design round. At Sierra, the round asked candidates to design an agent-based system.
If you're interviewing at an AI-first company, prepare to discuss how you'd architect systems where the core compute resource is a GPU, the workload is bursty and expensive, and the output is non-deterministic.
The Framework
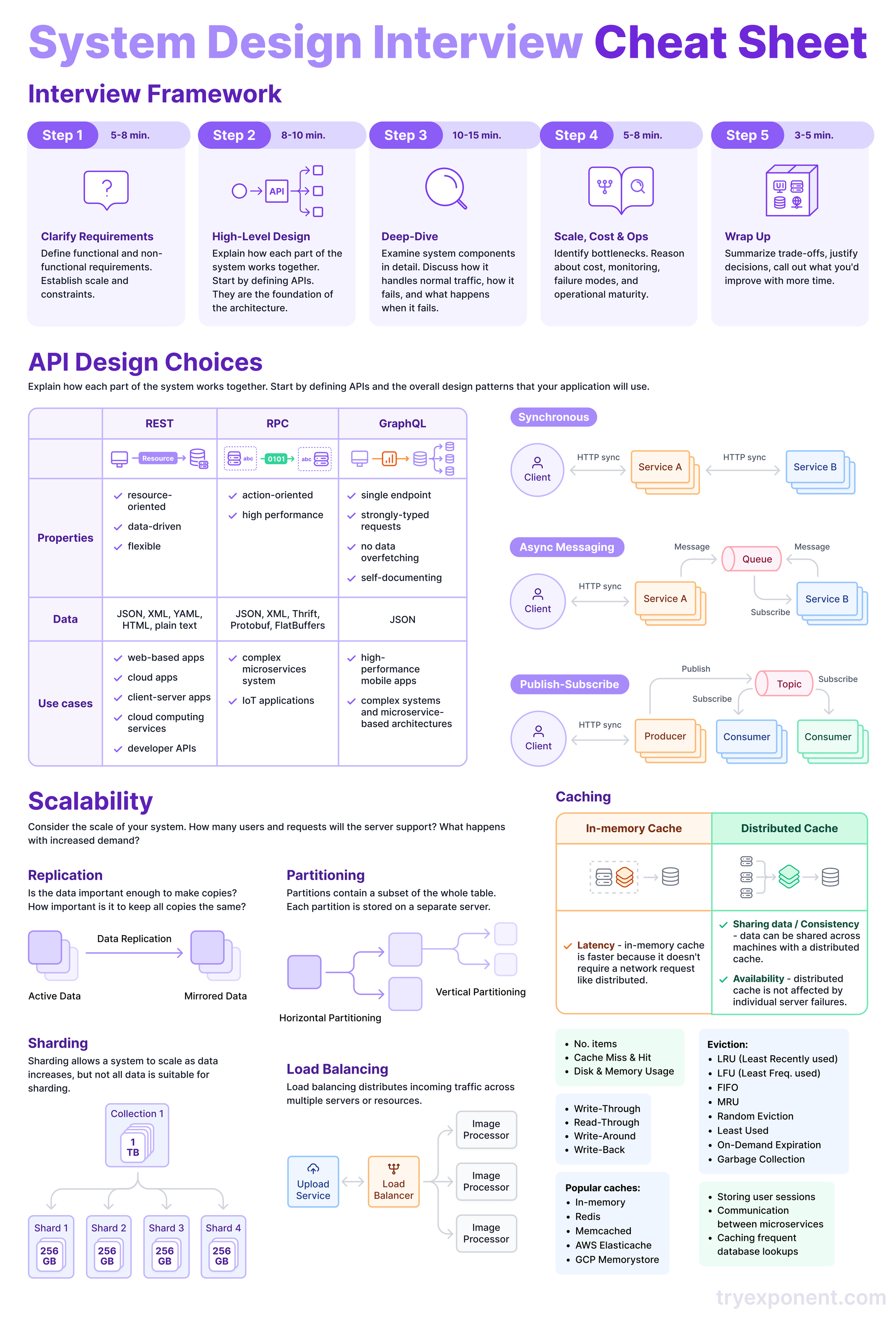
Regardless of company, format, or question, this five-step structure gives you a way to use your 45 to 60 minutes well.
Most companies still follow this general shape. Netflix, Stripe, and Amazon GenAI roles are notable exceptions.
Step 1: Clarify requirements (5–8 minutes)
Don't start designing before you understand the problem.
Ask about functional requirements. What does the system actually need to do? If the prompt is "Design TikTok," which features matter? Video upload? Feed generation? Search? Live streaming? The interviewer won't scope this for you. Propose a scope and get alignment.
Ask about non-functional requirements. What matters most between availability, consistency, latency, and cost? Ask about scale (how many users, how many requests per second, how much data) and access patterns (read-heavy or write-heavy, how soon after writing is data read).
State what you're excluding. "I'll focus on the feed generation and video upload services and leave user authentication and payments out of scope." This shows you can prioritize.
An Airbnb interviewer described the expected approach: "Come up with scale, functional requirements, non-functional requirements. Then establish constraints. Then jump into your main design." The candidates he sees succeed are the ones who ask good clarifying questions before drawing a single box.
Step 2: High-level design (8–10 minutes)
Sketch the system's core components. Start with the API layer (what endpoints exist, what data goes in and out), then show how the major services, databases, and caches connect.
Your goal is to confirm that the design satisfies all functional requirements. Don't go deep on any one component yet. Show the data flow for each core use case. If you're designing a messaging app, trace a message from the sender's client through the API, into storage, and out to the recipient.
Choose your communication protocols (REST, GraphQL, gRPC, WebSockets) and justify why. Choose your data storage approach and explain the reasoning. These choices should flow from your requirements, not from habit.
Step 3: Deep dive (10–15 minutes)
This is the highest-signal portion of the interview. You or the interviewer will select one or two components to examine in detail.
Go beyond performance tuning. Interviewers want to see you reason about three things simultaneously: how the component handles normal traffic, how it fails, and what happens when it fails.
An Airbnb interviewer told us he's specifically looking for "how candidates think about systems and failure modes."
At OpenAI, interviewers push designs to 10x, 100x, and 1000x the initial requirements to watch how the architecture evolves under pressure.
Consider how non-functional requirements affect your design choices. If the system requires transactions, discuss ACID properties and which database supports them. If data freshness matters, discuss how to speed up ingestion and processing.
If the data is large, discuss partitioning strategies and consistent hashing for load distribution.
"SQL vs. NoSQL" isn't actually the question most interviewers care about. Which specific engine, and why for this specific workload, is.
Step 4: Scale, cost, and operations (5–8 minutes)
Step back and stress-test the design. This step has expanded in 2026.
Interviewers at multiple companies now explicitly evaluate three things beyond raw scalability: cost reasoning, failure recovery, and operational maturity.
For bottlenecks: identify the constraint, propose a mitigation, discuss the trade-off, and recommend a path forward. What breaks at 10x scale? At 100x? Where are the single points of failure? Would a CDN help latency for globally distributed users? Are there scenarios (a viral post, a flash sale, a coordinated usage spike) that would overwhelm the system?
For cost: can you reason about when to use reserved versus spot instances? When caching saves money versus when it adds complexity that isn't worth it? When a serverless architecture is cheaper at low scale but explodes at high scale? You don't need to quote AWS pricing. You need to show you think about cost as a design constraint, not an afterthought.
For operations: mention monitoring, alerting, and observability before the interviewer asks. Logs, metrics, traces, dashboards. How would your team know something is broken at 3 AM? How would they debug it? Bringing this up unprompted signals you've actually run systems in production. Candidates who skip it signal they haven't.
Step 5: Wrap up (3–5 minutes)
Summarize what you designed, which trade-offs you made, and why.
Call out what you'd improve with more time: data migration strategies, CI/CD pipeline design, more granular access controls, geographic failover.
The interviewer knows you can't cover everything in 45 minutes. Showing you know what you deferred and why demonstrates judgment.
How to Prepare
Eight-week plan
Weeks 1–2: Build a mental library of building blocks. Load balancing, caching, relational and non-relational databases, message queues, CDNs, consistent hashing, replication, sharding, CAP theorem.
Don't memorize architectures for specific systems. Understand the building blocks so you can compose them under pressure. The most common failure mode in system design interviews is memorization.
Weeks 3–5: Work through 8 to 10 classic questions out loud, in 45-minute timeboxes. Use Excalidraw, Whimsical, or a physical whiteboard. Say your reasoning out loud even when practicing alone. The goal is building the muscle of real-time reasoning under time pressure, not producing perfect diagrams.
Weeks 6–7: Mock interviews with another engineer or through our peer mock interview tool. Pattern recognition only forms under pressure. An Airbnb interviewer who received nearly 15 offers during his own job search attributed his success to treating interviews as a daily practice. He conducted an interview every day, analyzed what worked and what didn't, and systematically improved his conversion rate over weeks.
Week 8: Company-specific prep using the breakdowns in this guide and our dedicated company interview guides. Review your weak spots. Don't learn anything new the week before. Sharpen what you have. Practice 1:1 system design mock interviews with an expert coach.
Two-week plan
Compress weeks 1–2 into three days of intensive fundamentals study.
Spend the remaining time on practice problems and at least two mock interviews. Focus on the most commonly asked questions for your target company.
If you're targeting AI-first companies
Add one week specifically for AI/LLM infrastructure patterns. Understand how batch inference works, how GPU clusters are managed, what retrieval-augmented generation involves, and how rate limiting works for LLM APIs.
You don't need to be an ML expert, but you need to understand the infrastructure patterns that support ML workloads.
Senior vs. Staff
The same question can be answered at a mid-level, senior, or staff level depending on how you approach it.
At the junior level, finding basic issues and demonstrating competence with testing and logic is the bar.
At the senior level, you're expected to be an expert in your vertical: understanding scalability, reliability, and maintainability, thinking about the implications of your design decisions for the product's future.
At the staff level, the differentiator is expanding your influence beyond your team, connecting dots across services, considering cross-team implications, and communicating with clarity.
In practice, staff-level candidates drive the interview. They propose scope rather than asking the interviewer to narrow it. They raise non-obvious concerns (data migration paths, backward compatibility, organizational boundaries) without being prompted.
And they demonstrate judgment about what to focus on: choosing the two most important components to examine in depth rather than trying to cover everything shallowly.
A staff candidate in the architecture review round at Airbnb, for example, is expected to articulate who the stakeholders were, why certain decisions were made, and how the project affected dependencies and cross-team work. The interviewer said the best candidates don't just explain the technical choices; they explain the reasoning behind the reasoning.
Key Concepts
These are the building blocks you'll use in every system design interview. For deep dives with video walkthroughs, see our system design course.
- Load balancing distributes traffic across servers to prevent bottlenecks. Know the difference between Layer 4 (transport) and Layer 7 (application) balancers, and when each applies.
- Caching stores frequently accessed data in memory. Understand cache-aside, write-through, and write-behind strategies, plus cache invalidation. Know when caching helps and when it introduces dangerous staleness.
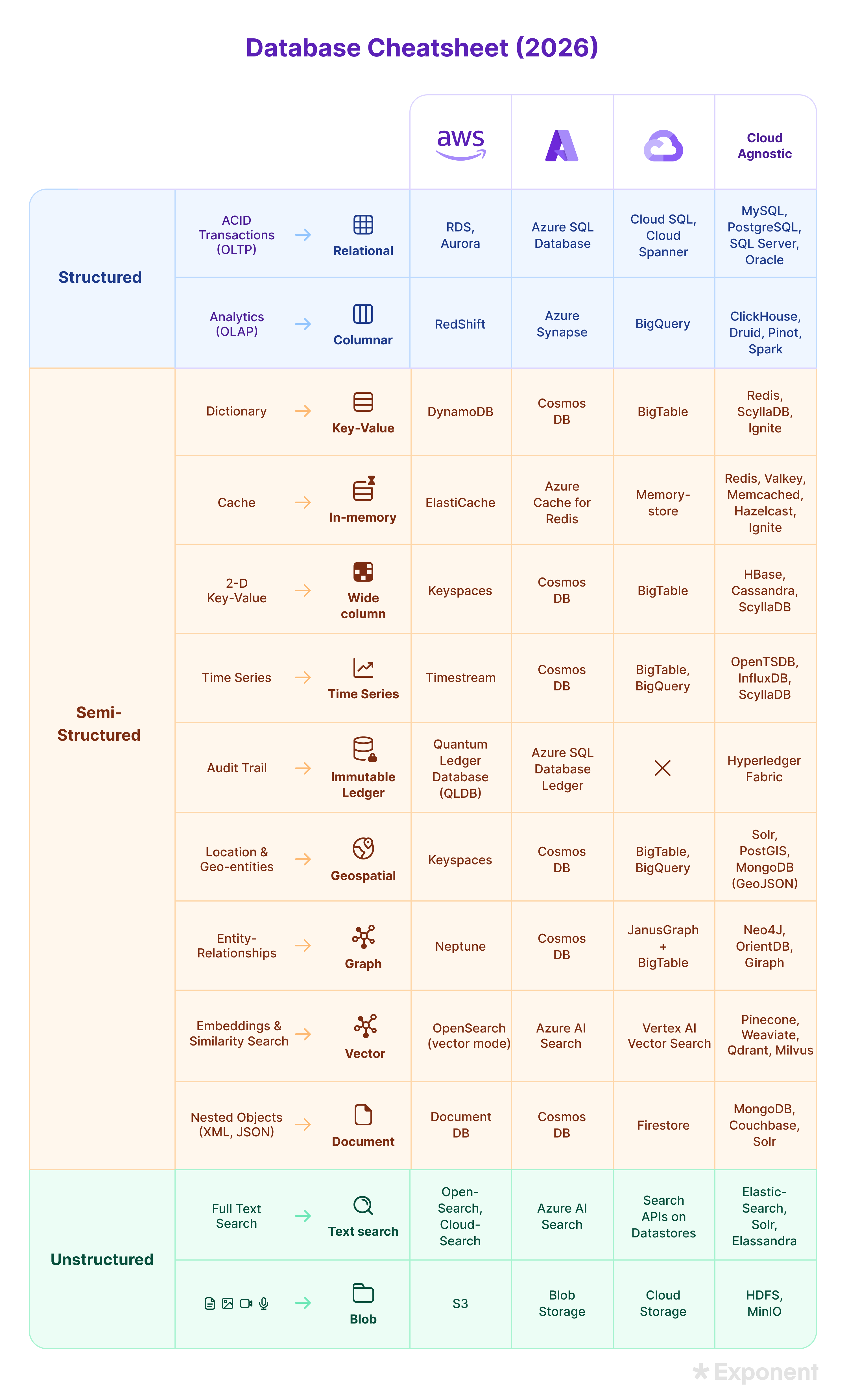
- Databases: know when to use relational (PostgreSQL, MySQL) versus non-relational (MongoDB, Cassandra, DynamoDB, Redis). The real question in 2026 isn't "SQL vs. NoSQL" but "which specific engine and why for this workload."
- Message queues enable asynchronous processing between services. Know when to use Kafka (high-throughput event streaming), SQS (simple job queues), or Pub/Sub (fan-out to multiple consumers).
- CDNs cache static content at edge locations near users. Required for any system serving media to a global audience.
- Consistent hashing distributes data across nodes while minimizing redistribution when nodes are added or removed. Used in distributed caches and databases.
- Replication creates copies of data for durability and read scaling. Sharding partitions data across nodes for write scaling. Different problems, different solutions, often used together.
- CAP theorem says that during a network partition, you choose between consistency and availability. Most production systems choose eventual consistency and design around it.
- API design: REST is the default. GraphQL gives clients flexible queries. gRPC is faster for service-to-service calls. WebSockets handle real-time bidirectional communication.
- Monitoring and observability: logs, metrics, traces, and alerts. Mentioning this unprompted during a system design interview signals real production experience.
FAQs
How long is a system design interview? Most run 45 to 60 minutes including introductions. Netflix rounds are consistently 60 minutes. Amazon sometimes compresses system design into a 20-minute section within a behavioral round.
Do all companies use whiteboarding? Whiteboarding is happening less in system design interviews. For instance, Netflix candidates often complete their round without any shared diagramming tool. Amazon GenAI roles may use a purely verbal format. Stripe uses HackerRank for multi-part coding/design problems. Most companies who do whiteboarding interviews will use a shared drawing tool like Excalidraw, Whimsical, or Google Drawings. Ask your recruiter which tool to prepare with.
Should I prepare differently for senior vs. staff level? Yes. At senior, demonstrate expertise in your domain and reason about scalability, reliability, and trade-offs. At staff, drive the interview: propose scope, raise cross-team concerns unprompted, demonstrate judgment about what matters most. Having more than one system design round is common for staff-level roles.
Do I need to know AI/ML for system design interviews in 2026? If you're interviewing at an AI-first company or for a role involving AI features, yes. You don't need to be an ML expert, but you should understand batch inference, GPU resource management, retrieval-augmented generation, and embedding pipelines. At traditional tech companies, AI system design questions are becoming more common but aren't universal yet.
What's the single most effective thing I can do to prepare? Practice out loud with another person. Reading about system design is useful but insufficient. The interview is a live conversation, and the skill of reasoning in real time under time pressure only develops through practice. Use our peer mock interview tool or find a practice partner.
Learn everything you need to ace your system design interviews.
Exponent is the fastest-growing tech interview prep platform. Get free interview guides, insider tips, and courses.
Create your free accountRelated Blog Posts
System Design Interview: Design a Rate Limiter

The 10 Best System Design Books to Sharpen Your Skills

How to Whiteboard for System Design Interviews

